IA Generativa

Imagine que você está ensinando uma criança a jogar xadrez. Você não explica todas as regras antecipadamente, mas permite que ela faça movimentos, e após cada partida você diz se ela ganhou ou perdeu. Através de centenas de jogos, a criança descobre por si mesma as estratégias que levam à vitória. É exatamente assim que funciona o aprendizado por reforço (Reinforcement Learning, RL) — um poderoso paradigma da inteligência artificial, no qual o algoritmo (agente) aprende a tomar decisões ótimas através de tentativa e erro, interagindo com o ambiente e recebendo recompensa por ações bem-sucedidas. Desde vencer campeões mundiais em go e xadrez até controlar robôs e otimizar sistemas complexos — o RL abre as portas para a criação de uma inteligência verdadeiramente autônoma e adaptativa.
1. Agente, ambiente, recompensa: fundamentos do paradigma RL
No cerne do aprendizado por reforço está um conceito simples, mas profundo, de interação do agente com o ambiente. A cada passo, o agente observa o estado atual do ambiente (por exemplo, a posição das peças no tabuleiro de xadrez) e escolhe uma ação (qual movimento fazer). Em resposta, o ambiente transita para um novo estado, e o agente recebe uma recompensa numérica (reward) — positiva para boas ações (que aproximam da vitória) e negativa (penalidade) para ações ruins. O objetivo do agente é maximizar a recompensa acumulada ao longo de todo o tempo, e não apenas o ganho imediato.
Para isso, o agente forma uma política — uma estratégia que, para cada estado, indica qual ação é melhor escolher. Ao aprender, o agente equilibra entre exploração (uso de ações boas já conhecidas) e exploração (tentativa de novas ações que podem levar a uma recompensa ainda maior no futuro). Algoritmos modernos de RL, como Deep Q-Networks (DQN), Proximal Policy Optimization (PPO) e algoritmos da família AlphaGo (Monte Carlo Tree Search + redes neurais), usam redes neurais profundas para representar a política ou função de valor, permitindo-lhes operar em ambientes extremamente complexos com espaços de estados enormes.
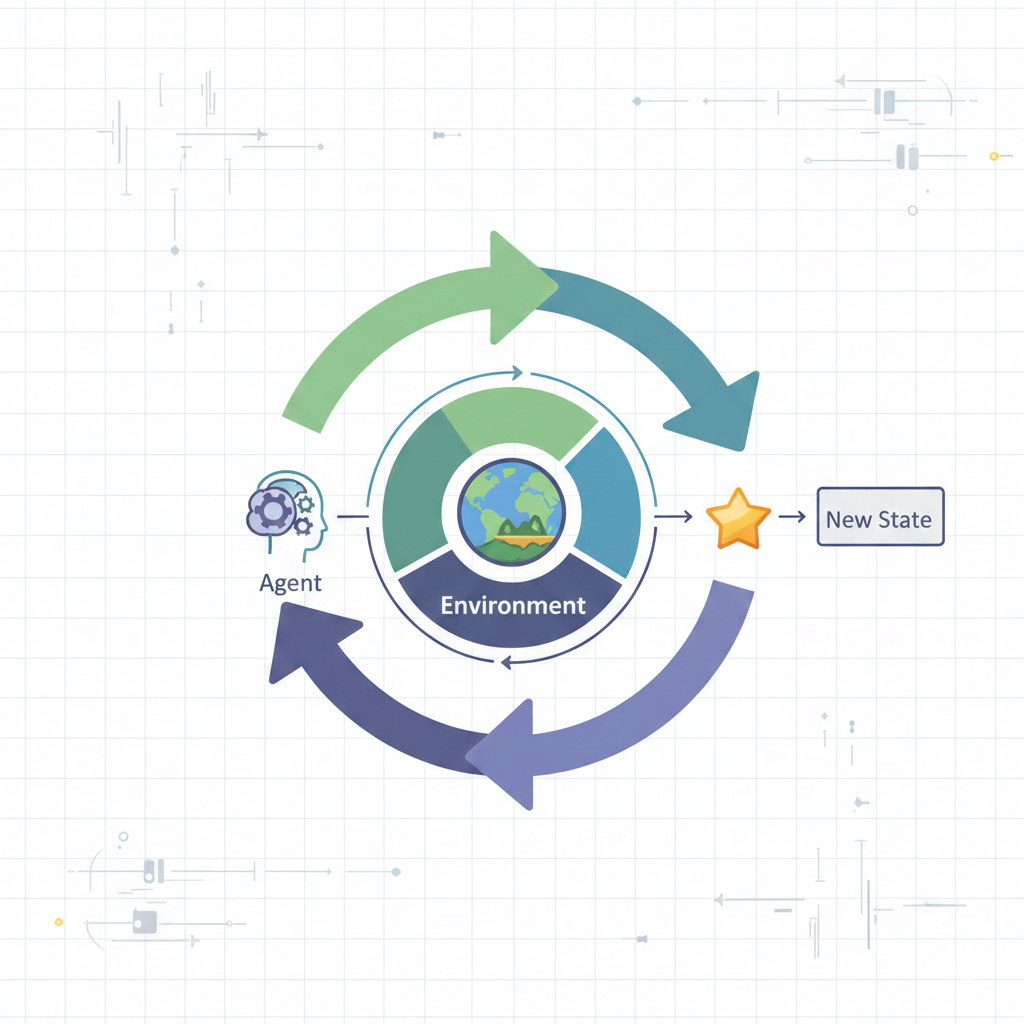
Ciclo do aprendizado por reforço: agente observa o estado, escolhe ação, recebe recompensa e novo estado
2. De jogos ao mundo real: AlphaGo, robótica e além
As vitórias mais famosas do RL estão associadas a jogos. AlphaGo da DeepMind, em 2016, venceu o campeão mundial no go, um jogo considerado inacessível para computadores devido ao número astronômico de posições possíveis. O algoritmo aprendeu jogando milhões de partidas contra si mesmo, descobrindo novas estratégias não humanas. Seu sucessor, AlphaZero, dominou não apenas o go, mas também xadrez e shogi, alcançando um nível sobre-humano do zero, sem qualquer conhecimento além das regras.
No entanto, o potencial do RL se estende muito além dos jogos. Na robótica, algoritmos de RL ensinam robôs a andar, manipular objetos e executar tarefas complexas no mundo físico através de simulações (por exemplo, no OpenAI Gym). Em carros autônomos, o RL ajuda a refinar estratégias de direção e tomada de decisão no tráfego simulado. A tecnologia também é usada para otimização de recursos em data centers (o Google usou RL para reduzir o consumo de energia), gestão de portfólio em finanças e até para personalização de recomendações e lances em publicidade online, onde o ambiente é o comportamento dos usuários.

Movimento do AlphaGo que surpreendeu o mundo e demonstrou a criatividade nascida do puro aprendizado por reforço
3. Desafios de simulação, segurança e futuro: agentes resilientes e explicáveis
O principal desafio da aplicação do RL no mundo real é o problema de transferência de conhecimento da simulação para a realidade (Sim2Real). O ambiente de simulação nunca é perfeitamente preciso. Um agente perfeitamente treinado no mundo virtual pode falhar completamente no físico devido a ruídos e peculiaridades imprevistas. Outro problema crítico é a segurança e estabilidade. Um agente que busca maximizar a recompensa pode encontrar e explorar "brechas" no ambiente (cheating), alcançando alta pontuação de maneiras destrutivas ou não previstas, o que é inaceitável em sistemas reais.
O futuro do aprendizado por reforço está na criação de agentes mais eficientes, seguros e explicáveis. Desenvolvem-se métodos de RL hierárquico, onde o agente aprende habilidades abstratas de alto nível que depois combina, acelerando o aprendizado. Pesquisa-se ativamente o aprendizado por reforço inverso, onde o objetivo é entender a recompensa que um especialista maximizou, apenas observando suas ações. Uma direção crucial é o aprendizado multitarefa e meta-aprendizado, permitindo que o agente se adapte rapidamente a novos ambientes desconhecidos com base em experiência prévia. E, finalmente, a integração do RL com grandes modelos de linguagem abre caminho para a criação de agentes que entendem instruções em linguagem natural e podem aprender em mundos complexos e parcialmente observáveis.
Conclusão
O aprendizado por reforço é, possivelmente, a abordagem mais próxima da inteligência "verdadeira" na IA, imitando o processo de aprendizado através da interação, que é característico de humanos e animais. Ele provou sua capacidade de encontrar soluções não óbvias e geniais em mundos bem definidos. O próximo grande desafio é transferir esse poder para o mundo real caótico, incerto e mutável, criando agentes que possam aprender e agir de forma segura e eficiente entre nós. O sucesso nessa direção abrirá a era de sistemas verdadeiramente autônomos, capazes de autoaprendizado contínuo e adaptação, o que será um marco não apenas na tecnologia, mas também na nossa compreensão da inteligência como tal.